Kolorierte Postkarten

Historische Postkarten in Schwarz-Weiß und in Farbe
Das Datenset der historischen Postkarten in den ÖNB Labs besteht aus Metadaten zu 34.846 digitalisierten Ansichtskarten aus den Jahren 1893 bis 1925, von denen 27.179 in Schwarz-Weiß und 7.667 in Farbe gedruckt wurden. Hier können Sie das Datenset durchstöbern. Das Datenset ist teil der größeren Menge aller historischen Postkarten der ÖNB, welche über das AKON Portal aufgerufen werden kann. Für die ÖNB Labs wurden jedoch nur die Postkarten mit Public Domain Mark ausgewählt.
Da ungefähr drei Viertel der Postkarten in unserem Datenset in Schwarz-Weiß gedruckt sind, stellte sich uns die Frage, ob ein Algorithmus aus dem Bereich der Computer Vision hier eingesetzt werden könnte um diese Postkarten einzufärben. Die reichliche Anzahl an Farbpostkarten verleitete uns zur Annahme, dass Methoden des Maschinellen Lernens eingesetzt werden können um einen Einfärbungsalgorithmus auf dieser Teilmenge zu trainieren. Zu Beginn des Projekts war ersichtlich, dass die Farbpalette der historischen Postkarten eine Schwierigkeit darstellen würde, denn diese unterscheidet sich deutlich von heutigen Fotografien. Die Unterschiede rühren wahrscheinlich durch Alterungsprozesse und – sich von den heutigen unterscheidende – Druckmethoden her.
Das Projekt von R. Zhang
Eines der freien (Open Source) Projekte zum Thema Einfärbung ist von Richard Zhang (Forscher bei Adobe Research) und Kollegen, welches auf zwei Veröffentlichungen basiert (siehe Colorful Image Colorization und Real-Time User-Guided Image Colorization with Learned Deep Priors). In beiden Fällen wird ein Convolutional Neural Network (CNN, siehe den blauen Teil in Abbildung 2) verwendet um ausgehend von einem Graustufenbild ein Farbbild zu erzeugen. Auf GitHub wird Code für eine Demo-Version des Programms bereitgestellt.
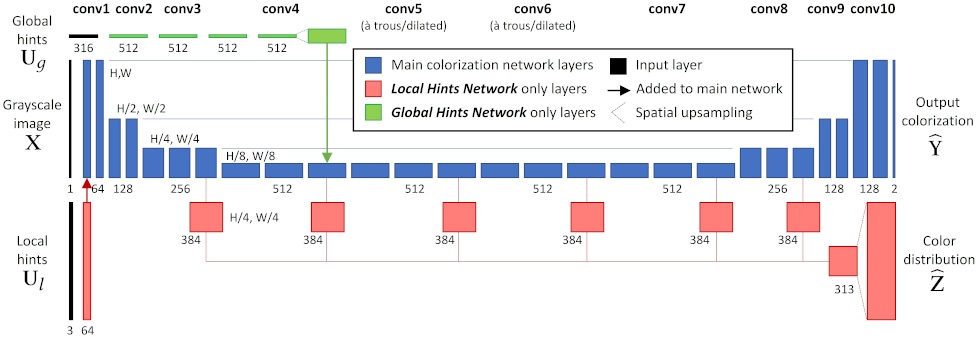
Die zwei in den Veröffentlichungen präsentierten Modelle wurden mithilfe eines sehr großen Datensets trainiert, welches mehr als eine Million Bilder beinhaltet. Da die Modelle den Lab-Farbraum verwenden, kann jedes Farbbild zum Training verwendet werden: Aus der Eingabe des L-Kanals (Helligkeit) erzeugen die Modelle einen ab-Kanal (Farbinformation), welcher mit dem ab-Kanal des Ausgangsbilds verglichen werden kann.
In Abbildung 3 ist die beispielhafte Anwendung der zwei Modelle (ECCV16 und SIGGRAPH17) von R. Zhang et al. auf eine historische schwarz-weiße Postkarte dargestellt. Typischerweise erzeugt das ECCV16-Modell ein farbigeres, saturiertes Bild, wogegen das SIGGRAPH17-Modell ein konsistenteres, glaubwürdigeres Bild liefert, das jedoch eine eintönigere Farbpalette besitzt. Beiden Modellen ist gleich, dass sie erfolgreich Himmel und Bäume einfärben, was wahrscheinlich auf deren große Präsenz in den Trainingsdaten zurückgeführt werden kann.



Training eines eigenen Netzwerkes
Um das SIGGRAPH17-Modell an den Rahmen der historischen Postkarten anzupassen verwenden wir die Methode des Transferlernens (transfer learning). Dazu stellen wir als erstes das Trainingsdatenset zusammen: Aus der Kollektion der historischen Postkarten (siehe hier für die Metadaten aller historischen Postkarten in den ÖNB Labs) haben wir nur die in Farbe gedruckten ausgewählt und sie mit der Auflösung 256 × 256 Pixel heruntergeladen. Dies vermeidet die Verwendung unnötigen Speicherbedarfs, denn die Modelle von R. Zhang et al. arbeiten mit dieser Auflösung. In Abbildung 4 geben wir einen Überblick über das Trainingsdatenset, welches insgesamt aus 7.667 Bildern besteht.

Als nächsten Schritt laden wir das SIGGRAPH17-Modell und fixieren alle Parameter bis auf die in der 10. Schicht. Danach trainieren wir die 10. Schicht des Netzwerkes mithilfe unseres Trainingsdatensets. Siehe unser GitLab Repositorium, wo wir Code für das Training und das Herunterladen der Trainingsdaten bereitstellen. Damit das Training in vertretbarer Zeit abläuft (in Stunden anstatt Tagen) empfehlen wir die Verwendung eines Systems mit GPU. Sie können Ihre eigene Hardware verwenden oder das Jupyter Notebook beispielsweise in Google colab (wo ein kostenfreier – jedoch limitierter – Zugang zu GPU Hardware für Machine Learning möglich ist) importieren und dort das Training durchführen.
Ergebnisse
Schließlich vergleichen wir die Ausgabe der zwei Modelle von R. Zhang et al. mit der unseres eigenen Netzwerkes. In Abbildung 5 ist die Einfärbung von 4 ausgewählten in Schwarz-Weiß gedruckten Postkarten dargestellt.
Da das Ausgangsmaterial in schwarz-weiß gedruckt ist gibt es kein objektives Maß für die Qualität der Kolorierung (d.h. es gibt keine "ground truth" für diese Bilder), Menschen können jedoch die Plausibilität der Farbbilder beurteilen. Im Großen und Ganzen zeigen die Bilder die durch unser trainiertes Netzwerk (genauer: durch Verwendung des SIGGRAPH17-Modells und Training seiner 10. Schicht auf unserer Farbpostkarten-Kollektion) erzeugt wurden glaubwürdige Farben. Jedoch weisen die Bilder meist eine historisch anmutende Grüntönung auf, was wahrscheinlich auf die vielen Postkarten im Trainingsdatenset mit grünen Landschaften zurückzuführen ist.
















Mitmachen
Hat diese Demonstration Ihr Interesse an Machine Learning geweckt? Würden Sie gerne selbst Ihre Schwarz-Weiß-Bilder einfärben? Schreiben Sie uns wenn Sie Fragen oder Feedback haben, wir würden uns freuen von Ihnen zu hören!
Der komplette Code ist verfügbar im Repositorium für das Projekt auf unserer öffentlichen GitLab-Plattform. Dort finden Sie (neben verschiedenen Python-Skripten) ein Jupyter Notebook, in welchem vorgeführt wird, wie unser Netzwerk trainiert wird.