Österreichische Zeitungen in turbulenten Zeiten – ein digitaler Vergleich
Im folgenden Beitrag stellt Thomas Kirchmair einen Ansatz zum Vergleich der Wiener Zeitung und des Salzburger Intelligenzblatts im 18. Jahrhundert vor. Im Rahmen eines zweimonatigen Projekts an den ÖNB Labs erprobte er die digitale Methode des Topic Modelling, mithilfe derer die (thematische) Struktur der Texte erforscht und verglichen werden kann.

Die beiden Zeitungen
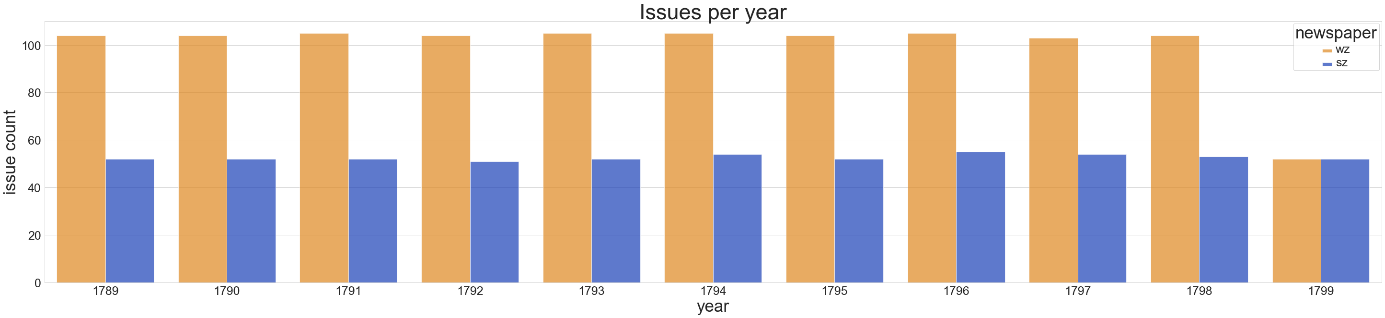
Die Wiener Zeitung (WZ) wird seit 1703 veröffentlicht und gilt als die älteste noch erscheinende Zeitung der Welt. Sie wird im 18. Jahrhundert posttäglich, also mittwochs und samstags, veröffentlicht (Berger, 1953). Inhaltlich fokussiert sich die Wiener Zeitung auf Informationen für Adelige, wie etwa amtliche Kundmachungen, Geschehnisse in der Stadt und Inserate, ebenso wie (internationale) politische Begebenheiten (Mader-Kratky, Resch & Scheutz, 2019). Das Salzburger Intelligenzblatt (SZ) hingegen stellt eine Beilage zur Oberdeutschen Zeitung dar und erscheint ab 1784 wöchentlich. Thematisch enthält es amtliche Kundmachungen, nützliche und belehrende Artikel mit ökonomischen oder geschichtlichen Schwerpunkten und diverse Inserate und Anzeigen. Zusätzlich verfügen manche Ausgaben über unterhaltende Artikel, etwa zu Mode und Kunst (Demelmair, 2011). Der untersuchte Zeitraum liegt zwischen 1789 und 1799. Dieser wurde aufgrund des Ersterscheinungsdatums des Salzburger Intelligenzblatts und dessen in den Anfangsjahren nur in geringem Umfang verfügbaren Textmenge festgelegt. Die beiden Datensets wurden über ANNO bezogen, diese umfassen die Volltexte, nicht jedoch die ebenso verfügbaren Faksimiles. Die Wiener Zeitung umfasst in dem Zeitraum 1304 Ausgaben, das Salzburger Intelligenzblatt 630 Ausgaben. Die genaue Verteilung der Ausgaben pro Jahr ist in Abbildung 2 ersichtlich.
Um die Texte verarbeiten zu können, müssen diese tokenisiert werden. Dabei wird der Zeichenstrom in kleinere Einheiten, sogenannten Tokens (Laufwörter), zerlegt (Webster & Kit, 1992). Dieser Vorgang wird mithilfe des SoMaJo Tokenizers durchgeführt, da dieser ein State-of-the-Art Tool für deutschsprachige Texte darstellt. Der Tokenizer ist primär für Texte in sozialen Medien intendiert, diese weisen jedoch Ähnlichkeiten zu historischen Sprachdaten auf, wie etwa die hohe sprachliche und graphematische Variation, weshalb wir dieses Tool verwenden. Das Korpus der Wiener Zeitung umfasst 34.126.677 Tokens, das Korpus des Salzburger Intelligenzblatts umfasst 3.031.989 Tokens. Die Daten werden in einem nächsten Schritt intensiv aufbereitet, um sie für das Topic Modelling verwenden zu können. Die Datenaufbereitung umfasst das Lowercasing der Daten, das Entfernen von Stopwords (z.B. bey, am, das), von Anführungszeichen, Kommata, von Leerzeichen vor Satzzeichen, von Satzzeichen am Ende eines Strings, von Wörtern die Nummern oder Spezialzeichen enthalten, von Bindestrichen und Gleichheitszeichen, von jeglichen Satzzeichen, von Wörtern bestehend aus drei oder weniger Zeichen, von multiplen Leerzeichen und von Wörtern die bis zu fünf Mal vorkommen. Diese Bereinigungsschritte werden mittels regulärer Ausdrücke ausgeführt, wichtig ist dabei auch die Reihenfolge der einzelnen Schritte. Der gesamte Code ist als Jupyter Notebook im Gitlab der ÖNB Labs verfügbar.
Komparative Methoden
Um Korpora vergleichen zu können, gibt es verschiedene Methoden, viele davon können jedoch nur bedingt für historische Textdaten verwendet werden. So können wir etwa den Wortschatz der beiden Korpora vergleichen. Das unterschiedliche Vokabular der Wiener Zeitung und des Salzburger Intelligenzblatts können wir mithilfe eines Mengendiagramms grafisch darstellen, wie in Abbildung 3 ersichtlich ist.
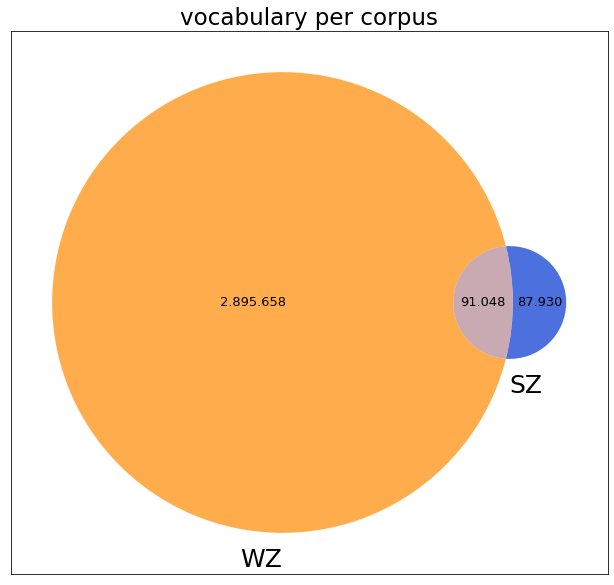
Dabei sehen wir, dass das Vokabular der Wiener Zeitung sehr viel größer ist als jenes des Salzburger Intelligenzblatts. Während sich das Salzburger Intelligenzblatt 50.87 % des Vokabulars mit der Wiener Zeitung teilt, sind es umgekehrt lediglich 3.05 % des Vokabulars das sich die Wiener Zeitung mit dem Salzburger Intelligenzblatt teilt. Ein weiterer, relativ neuer Ansatz zum Vergleich von Korpora ist die Berechnung der semantischen Ähnlichkeit, bei der Dokumente zu Vektoren basierend auf Wortfrequenzen umgewandelt werden und deren Differenz berechnet wird. Hierfür wird ein Modell von Sahaj Tomar über Hugging Face verwendet, das auf dem vortrainierten Sprachmodell GBERT basiert. Diesem Ansatz nach sind die beiden Zeitungen zu 9.53 % semantisch ähnlich. Allerdings bieten diese Methoden keine Möglichkeit, inhaltliche oder strukturelle Merkmale der Texte zu erfassen. Aus diesem Grund erproben wir nun einen Ansatz mittels Topic Modelling.
Topic Modelling
Unter Topic Modelling werden verschiedene Verfahren der natürlichen Sprachverarbeitung zusammengefasst, die automatisch Topics aus Textdaten extrahieren. Es handelt sich um Methoden des unüberwachten maschinellen Lernens. Dabei werden Tokens die statistisch häufiger gemeinsam auftreten zu Topics zusammengefasst. Hierbei muss angemerkt werden, dass Topics nicht zwingend mit Themen im engeren Sinne gleichgesetzt werden können, da sie auf statistischen Berechnungen basieren. Die bekannteste und am einfachsten zu implementierende Methode, das Latent Dirichlet Allocation Model, kurz LDA, stammt von Blei, Ng & Jordan (2003) und wird in vielen verschiedenen Bereichen eingesetzt, unter anderem etwa für die Analyse historischer Dokumente, wissenschaftlicher Publikationen und Literatur, in den computergestützten Sozialwissenschaften und in der maschinellen Translation (Boyd-Graber, 2017). Da die Daten in ANNO durch ein OCR-Verfahren gewonnen wurden, wird jedoch ein sogenanntes Embedded Topic Model (ETM) verwendet. Die Textqualität bei automatisch digitalisierten Texten ist schwankend, etwa aufgrund von Sprachvariation, historischen Schriftarten oder der materiellen Qualität der Datenträger (Österreichische Nationalbibliothek, 2022). Das ETM-Modell jedoch ist robuster gegenüber fehlerbehaftetem Text und einem großen Vokabular als das klassische LDA-Modell (Zosa et al., 2021). Das ETM-Modell stellt eine Weiterentwicklung des LDA-Modells dar, hierbei werden Wortvektoren zur Repräsentation der einzelnen Tokens als auch der Topics verwendet, wodurch aussagekräftigere Ergebnisse generiert werden können. Dabei liegt dem Embedded Topic Model ein vortrainiertes Sprachmodell zugrunde, das Modell wird jedoch an den Korpusdaten weiter trainiert (Dieng, Ruiz & Blei, 2020).
Vorgehensweise
Nachdem die Daten, bestehend aus dem jeweiligen Korpus im tsv.-Format und dem dazugehörigen Vokabular im txt-Format, aufbereitet wurden, wird das Modell im sogenannten OCTIS-Framework implementiert, welches die automatische Evaluation der Ergebnisse ermöglicht (Terragni, Fersini, Galuzzi, Tropeano & Candelieri, 2021). Die unterschiedlichen Parameter, zum Beispiel die Anzahl der Topics, der Algorithmen können darin automatisch initialisiert und manuell angepasst werden. So können wir bestmögliche Resultate erhalten. Die Parameter umfassen unter anderem die Anzahl der Topics, die Anzahl der Epochen, die Größe der Word Embeddings und die Dropout-Rate. Anschließend trainieren wir pro Zeitungskorpus ein Modell mit den Standardeinstellungen. Nach einer manuellen Sichtung der Ergebnisse werden jeweils maximal drei Parameter gleichzeitig darauf optimiert, dass der Coherence Score möglichst groß ist. Der Coherence Score stellt einen Wert dar, der die Ähnlichkeit von Tokens die ein Topic bilden beschreibt (Röder, Both & Hinneburg, 2015). Das Modell wird anschließend aktualisiert und iterativ evaluiert, bis die gewünschten Parameter die optimalen Werte erreicht haben. Der Coherence Score erreicht für die Wiener Zeitung einen Wert von 0.2431, für das Salzburger Intelligenzblatt einen Wert von 0.4386.
Ergebnisse
Pro Modell werden eine Topic-Word-Matrix, eine Topic-Document-Matrix, die Topics und eine Test-Topic-Document-Matrix ausgegeben. Die Topic-Word-Matrix gibt die Wahrscheinlichkeit von jedem einzelnen Token an, in einem der Topics vorzukommen. Die Topic-Document-Matrix beschreibt die Verteilung der Topics pro Dokument. Die Topics bestehen aus jeweils zehn Wörtern und die Test-Topic-Document-Matrix stellt die Topic-Document-Matrix des Testsets dar. Aus der Wiener Zeitung werden 99 Topics extrahiert, aus dem Salzburger Intelligenzblatt sind es 66. Wir interpretieren die Topics manuell und ordnen diese verschiedenen Kategorien zu, die aus dem Material abgeleitet werden. Daneben gibt es auch Topics, die nicht sinnvoll interpretiert werden können, da sie aus Tokens bestehen, die aufgrund statistischer Inferenzen ein Topic bilden, semantisch jedoch nicht sinnvoll gruppiert sind (z.B. ‚anna bevor jahr freye feld widrige such klara eigenschaft märz‘). Diese werden aus der Analyse ausgeschlossen. Ausgehend von feineren Kategorien wird interpretativ auf gröbere Themen rückgeschlossen. Insgesamt konnten wir 46 verschiedene Themen identifizieren, 17 davon sind ausschließlich in der Wiener Zeitung, 19 ausschließlich im Salzburger Intelligenzblatt, und zehn in beiden Zeitungen zu finden. Die Verteilung der Topics ist in der Abbildung 4 ersichtlich. Anzumerken ist hierbei jedoch, dass deren Häufigkeit im Diagramm nicht berücksichtigt wird.
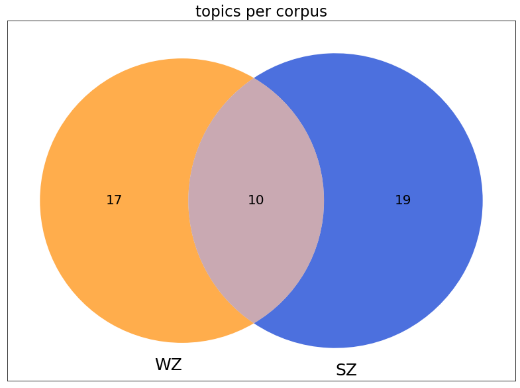
Dabei wird ersichtlich, dass die Wiener Zeitung und das Salzburger Intelligenzblatt viele Themen teilen, das allerdings in einem unterschiedlichen Ausmaß. In Abbildung 5 sind die am stärksten divergierenden Themen grafisch dargestellt, die als Grundlage zur weiteren Interpretation dienen.
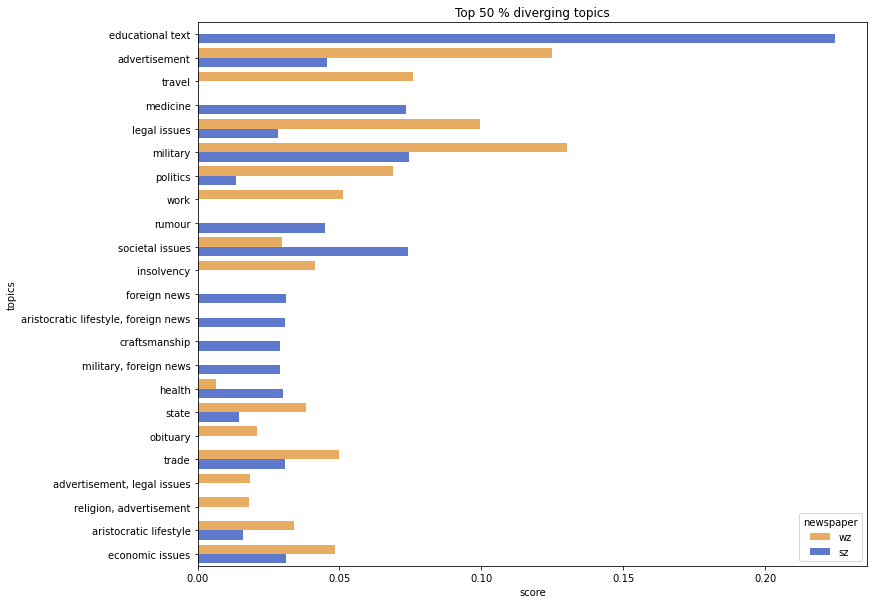
So legen die Ergebnisse der Modelle nahe, dass in der Wiener Zeitung mehr ‚advertisements‘, also Inserate, enthalten sind als im Salzburger Intelligenzblatt. Daneben gibt es auch Themen, die lediglich in einer Zeitung auftreten, wie etwa ‚educational texts‘ und ‚rumours‘ im Salzburger Intelligenzblatt oder ‚work‘ und ‚insolvency‘ in der Wiener Zeitung. Generell zeigt sich, dass in der Wiener Zeitung vermehrt Themen enthalten sind, die tendenziell als eher faktenbasiert und staatsbezogen („hard news“) eingeordnet werden können (‚legal issues‘, ‚military‘, ‚politics‘, ‚work‘, ‚insolvency‘, ‚state‘, ‚obituary‘, ‚trade‘, ‚economic issues‘). Im Salzburger Intelligenzblatt treten hingegen tendenziell eher meinungsbasierte und personenbezogene Themen auf („soft news“), wie etwa ‚educational text‘, ‚medicine‘,‘ rumour‘, ‚societal issues‘, ‚craftsmanship‘ oder ‚health‘. Diese Ergebnisse stehen mit den bisherigen Forschungen im Einklang, die die Wiener Zeitung als eher staatsorientiert, das Salzburger Intelligenzblatt als aufklärerisch beschreiben (vgl. Mader-Kratky, Resch & Scheutz, 2019; Demelmair, 2011).
Durch den innovativen Ansatz konnten wir zeigen, dass zum Vergleich historischer Dokumente Topic Modelling als Methode geeignet ist. Dabei ist historisches (Sprach-)Wissen unerlässlich, da sich die Interpretation der Topics als sehr komplex darstellt. Die Vertrautheit mit dem Material ist daher zur Interpretation der Ergebnisse eine notwendige Voraussetzung. Darüber hinaus müssen die Topics mit Vorsicht interpretiert werden, da die Ergebnisse des Models nur Ausschnitte aus der Gesamtheit der Daten darstellen. So kann es etwa vorkommen, dass aufgrund geringer oder fehlender statistischer Häufung von Tokens keine Topics gebildet werden, obwohl diese zur Interpretation der Daten durchaus beitragen könnten. Um die Qualität der Ergebnisse zukünftig zu erhöhen würde es sich anbieten, das dem ETM-Algorithmus zugrundeliegende, vortrainierte Sprachmodell durch ein Modell zu ersetzen, welches an historischen Daten trainiert wurde, da dieses aktuell noch auf modernen Texten basiert. Zusätzlich wäre es auch sinnvoll, die Sprachdaten mithilfe eines Lemmatizers, die Tokens in ihre Grundform zu transformieren, jedoch gibt es momentan noch kein geeignetes Tool für historische Texte. Nichtsdestotrotz weist die Methode ein großes Potenzial zur Untersuchung weiterer, auch größerer Bestände historischer Zeitungen auf, wie sie die Österreichische Nationalbibliothek anbietet.
Der vollständige Code ist im Repositorium für das Projekt auf unserer öffentlichen GitLab-Plattform verfügbar. Dort finden Sie mehrere Jupyter Notebooks zur Datenaufbereitung, zu den Modellen und deren Analyse, zudem die herangezogenen Quelldaten.
Über den Autor: Thomas Kirchmair, Bakk. BA absolvierte im Sommer 2022 ein zweimonatiges Praktikum an den ÖNB Labs an der Hauptabteilung Digitale Bibliothek.
Mitmachen
Hat dieses Fallbeispiel Ihr Interesse an Topic Modelling geweckt? Oder möchten Sie die vorgestellte Methode an anderen Datensätzen der Österreichischen Nationalbibliothek erproben? Schreiben Sie uns, wenn Sie Fragen oder Feedback haben, wir freuen uns von Ihnen zu hören!
Literatur
- Berger, M. (1953). „Wiennerisches Diarium“ 1703–1780. Ein Beitrag zur Entwicklung des Verhältnisses zwischen Staat und Presse. Dissertation: Universität Wien.
- Blei, D. M., Ng, A. Y. & Jordan, M. I. (2003). Latent Dirichlet Allocation. Journal of Machine Learning Research 3, 993-1002.
- Boyd-Graber, J. (2017). Applications of Topic Models. Foundations and Trends® in Information Retrieval, 11(2-3), 143-296. DOI: 10.1561/1500000030
- Demelmair, E. (2011). Kultur- und Begriffstransfer zwischen dem Fürstentum Salzburg und dem revolutionären Frankreich um 1800. Masterarbeit: Universität Wien.
- Dieng, A. B., Ruiz, F. J. R., & Blei, D. M. (2020). Topic Modeling in Embedding Spaces. Transactions of the Association for Computational Linguistics 8, 439-453. DOI: 10.1162/tacl_a_00325
- Mader-Kratky, A., Resch, C. & Scheutz, M. (2019). Das Wien[n]erische Diarium im 18. Jahrhundert. Neue Sichtweisen auf ein Periodikum im Zeitalter der Digitalisierung. In Mader-Kratky, A., Resch, C. & Scheutz, M. (eds), Das Wien[n]erische Diarium im 18. Jahrhundert. Digitale Erschließung und neue Perspektiven (Teil I). Wiener Geschichtsblätter 74(2), 93-113.
- Österreichische Nationalbibliothek (2022). Austrian Books Online. https://www.onb.ac.at/digitale-angebote/austrian-books-online (24.08.2022)
- Röder, M., Both, A. & Hinneburg, A. (2015). Exploring the Space of Topic Coherence Measures. WSDM '15: Proceedings of the Eighth ACM International Conference on Web Search and Data Mining, 399-408. DOI: 10.1145/2684822.2685324
- Terragni, S., Fersini, E., Galuzzi, B. G., Tropeano, P. & Candelieri, A. (2021). OCTIS: Comparing and Optimizing Topic models is Simple!. Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations, 263–270. DOI: 10.18653/v1/2021.eacl-demos.31
- Webster, J. J. & Kit, C. (1992). Tokenization as the initial phase of NLP. COLING '92: Proceedings of the 14th conference on Computational linguistics 4, 1106-1110. DOI: 10.3115/992424.992434
- Zosa, E., Mutuvi, S., Granroth-Wilding, M. & Deucet, A. (2021). Evaluating the Robustness of Embedding-based Topic Models to OCR Noise. In Ke, H.R., Lee, C.S. & Sugiyama, K. (eds), Towards Open and Trustworthy Digital Societies. ICADL 2021. Lecture Notes in Computer Science 13133, 392-400, Springer. DOI: 10.1007/978-3-030-91669-5_30